Nella statistica e nell'apprendimento automatico, il compromesso bias-varianza (in inglese bias-variance tradeoff) è la proprietà di un modello secondo cui la varianza del parametro stimato tra i campioni può essere ridotta aumentando il bias nei parametri stimati. Il dilemma o problema della bias-varianza sta nel conflitto nel tentativo di minimizzare contemporaneamente queste due fonti di errore che impediscono agli algoritmi di apprendimento supervisionato di generalizzare oltre il loro insieme di addestramento (o training set):
- L'errore di bias è un errore derivante da presupposti errati nell'algoritmo di apprendimento. Un elevato bias può far sì che un algoritmo manchi le relazioni rilevanti tra le caratteristiche e gli output di destinazione (underfitting).
- La varianza è un errore dovuto alla sensibilità a piccole fluttuazioni nel training set. Un'elevata varianza può derivare da un algoritmo che modella il rumore casuale nei dati di addestramento (overfitting).
La scomposizione bias-varianza è un modo per analizzare l'errore di generalizzazione atteso di un algoritmo di apprendimento rispetto a un particolare problema come somma di tre termini, il bias, la varianza e una quantità chiamata errore irriducibile, risultante dal rumore nel problema stesso.
Motivazione
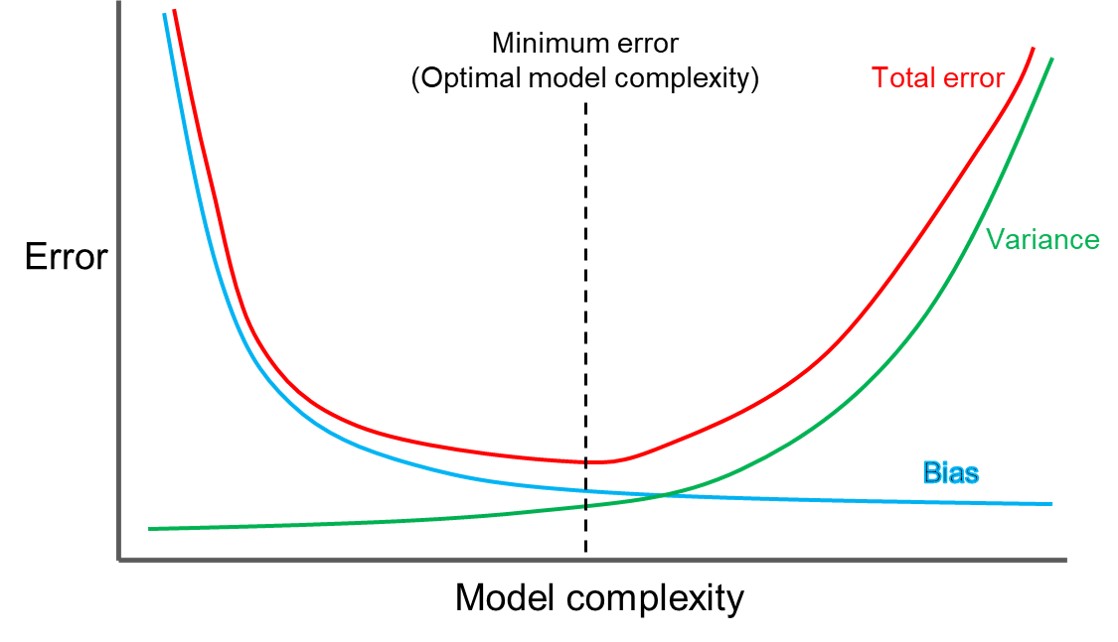
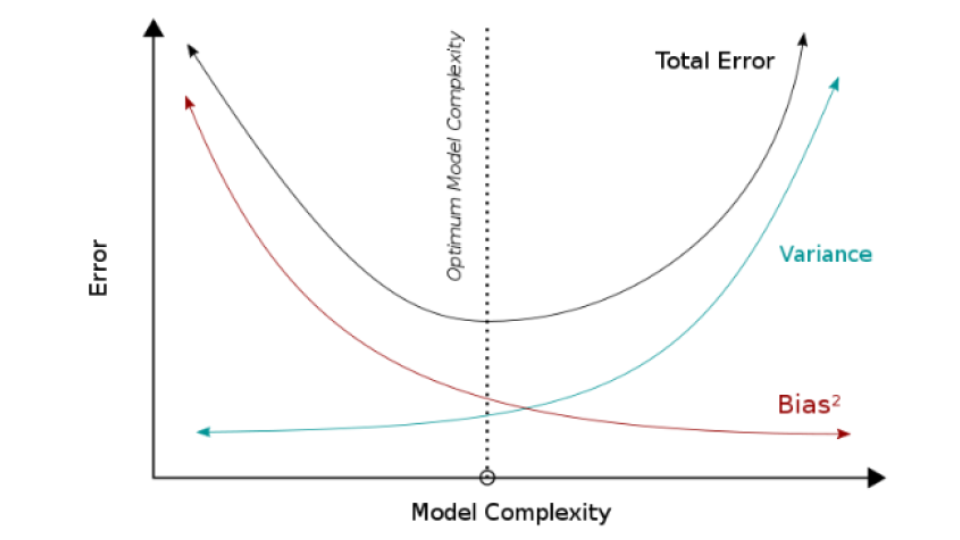
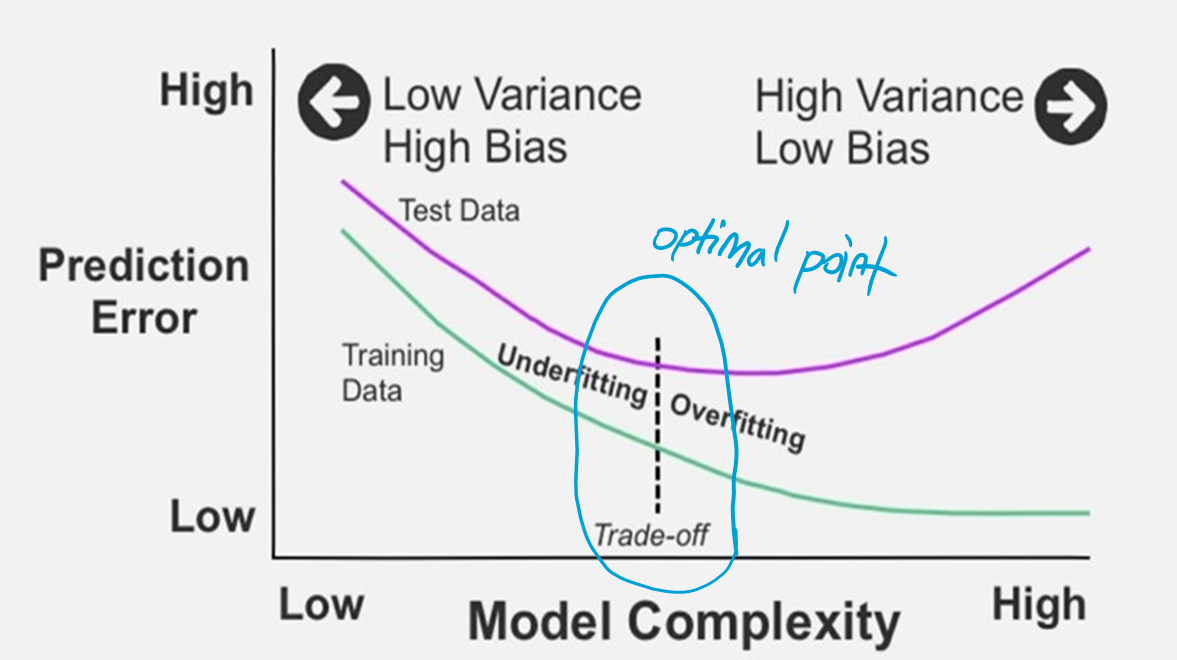
Il compromesso bias-varianza è un problema centrale nell'apprendimento supervisionato. Idealmente, si vuole scegliere un modello che catturi con precisione le regolarità nei suoi dati di addestramento, ma che generalizzi anche bene ai dati non visti. Sfortunatamente, in genere è impossibile fare entrambe le cose contemporaneamente. I metodi di apprendimento ad alta varianza possono essere in grado di rappresentare bene il loro set di training, ma rischiano di adattarsi eccessivamente ai dati rumorosi o non rappresentativi. Al contrario, gli algoritmi con alto bias producono in genere modelli più semplici che potrebbero non riuscire a catturare regolarità importanti (vale a dire underfit) nei dati. Nel primo caso si parla di overfitting e nel secondo di underfitting.
È una comune fallacia presumere che i modelli complessi debbano avere un'elevata varianza; mentre i modelli ad alta varianza sono "complessi" in un certo senso, non è necessariamente vero il viceversa. Inoltre, bisogna stare attenti a come definire la complessità: in particolare, il numero di parametri utilizzati per descrivere il modello è una misura scarsa della complessità. Ciò è illustrato dal seguente esempio. Il modello ha solo due parametri (), ma può interpolare qualsiasi numero di punti oscillando con una frequenza sufficientemente alta, risultando sia in un elevato bias che in un'elevata varianza.
Intuitivamente, la distorsione viene ridotta utilizzando solo le informazioni locali, mentre la varianza può essere ridotta solo facendo la media su più osservazioni, il che significa intrinsecamente utilizzare le informazioni provenienti da una regione più ampia. Per un esempio illuminante, vedere la sezione sui vicini più vicini o la figura a destra. Per bilanciare la quantità di informazioni utilizzate dalle osservazioni vicine, un modello può essere "lisciato" tramite regolarizzazione esplicita, come lo shrinkage (restringimento).
Scomposizione bias-varianza dell'errore quadratico medio
Si supponga di avere un training set , composto da un insieme di punti e valori reali associato a ciascun punto , e si assuma l'esistenza di una funzione , dove il rumore ha media nulla e varianza .
L'obiettivo è trovare una funzione che approssima la vera funzione nel miglior modo possibile, mediante un algoritmo di apprendimento basato sul training set. Nello specifico, "nel miglior modo possibile" significa richiedere che l'errore quadratico medio tra e , ovvero , sia minimo, sia per sia per i punti al di fuori del campione. Naturalmente, dal momento che i valori contengono rumore , ogni funzione che approssima avrà un "errore irriducibile".
Trovare una che generalizza a punti al di fuori del set di addestramento può essere fatto con uno qualsiasi degli innumerevoli algoritmi utilizzati per l'apprendimento supervisionato. Ad ogni modo, per ogni funzione , è possibile il suo errore atteso su un nuovo campione come segue:
dove
e
Il valore di espettazione spazia su diverse scelte del set di allenamento , tutti campionati dalla stessa distribuzione congiunta . I tre termini rappresentano:
- il quadrato del bias del metodo di apprendimento, che può essere pensato come l'errore causato dalle ipotesi semplificative incorporate nel metodo. Ad esempio, quando si approssima una funzione non lineare utilizzando un metodo di apprendimento per modelli lineari, ci saranno errori nelle stime a causa di questa ipotesi;
- la varianza del metodo di apprendimento, o, intuitivamente, quanto il metodo di apprendimento si muoverà intorno alla sua media;
- l'errore irriducibile .
Poiché tutti e tre i termini non sono negativi, l'errore irriducibile forma un limite inferiore all'errore atteso su campioni invisibili.
Più complesso è il modello vale a dire, più punti dati acquisirà e minore sarà la distorsione. Tuttavia, la complessità farà "spostare" maggiormente il modello per acquisire i punti dati, e quindi la sua varianza sarà maggiore.
Derivazione
La derivazione della scomposizione bias-varianza per l'errore al quadrato procede come segue. Per comodità di notazione, si abbrevia , e si lascia cadere il pedice sui nostri operatori di aspettativa. Innanzitutto, per definizione, per qualsiasi variabile casuale , si ha
Riordinando, si ottiene:
Da quando è deterministico, cioè indipendente da ,
Così, dato e (perché è rumore), implica
Inoltre, poiché
In definitiva, poiché e sono indipendenti,
Infine, la funzione obiettivo MSE si ottiene prendendo il valore di aspettativa :
Note